binned_binom_proportion¶
- astropy.stats.binned_binom_proportion(x, success, bins=10, range=None, confidence_level=0.68269, interval='wilson')[ソース]¶
連続変数ボックス中の二項割合と信頼区間
xそれがそうです。データ点ペアのセットが与えられ、その中で
x値は連続的に分布しておりsuccess値は二項(“成功/失敗”または“真/偽”)であるので,根拠を教えてくださいx値をとり,各倉位における二項割合(成功スコア)と信頼区間を計算する.- パラメータ
- x配列
価値観。
- successブール配列.
- bins整数またはスカラーシーケンス、オプション
Binsがintであれば,与えられた範囲(デフォルトでは10)内の等幅ボックス数を定義する.倉位がシーケンスである場合、最右の辺を含む倉位縁を定義し、不均一な倉位幅を可能にする(この場合、‘Range’は無視する)。
- range(浮動小数点数、浮動小数点数)、オプション
ゴミ箱の下限範囲と上限範囲.もし…。
None(デフォルト)、範囲は(x.min(), x.max())それがそうです。範囲外の値は無視されるだろう。- confidence_level浮動、オプション
範囲内でなければならない [0, 1] それがそうです。信頼区間における期待確率内容
(p - perr[0], p + perr[1])各ゴミ箱にあります。デフォルト値は0.68269である.- interval{‘Wilson’,‘Jeffreys’,‘Flat’,‘Wald’},オプション
各倉位における二項割合の信頼区間を計算するための式.参照してください
binom_conf_interval間隔を定義するために用いられる.“Wilson”、“Jeffreys”、“Flat”区間は通常類似した結果を与える。“ウィルソン”の方が早いはずですが、“ジェフリー”と“フラット”の方が少しいいですが、仮説の優先度に違いがあります。通常“Wald”間隔の使用は推奨されていない.これらの情報を提供するのは比較のためである.デフォルト値は‘Wilson’である.
- 返品
- bin_ctrNdarray
ゴミ箱の中心価値。何の項目もないゴミ箱は返品されません。
- bin_halfwidthNdarray
それぞれの倉庫の半幅は
bin_ctr - bin_halfwidthそしてbin_ctr + bins_halfwidthそれぞれのゴミ箱の左側と右側を与える.- pNdarray
それぞれのポジションの効率です
- perrNdarray
形状(2,len(P))の2次元配列は,個々のビンにおけるp上と下の不確実性を表す.
参考
binom_conf_interval各ビンにおける信頼区間を推定するための関数.
注意事項
この機能には
scipyすべての間隔タイプに適用される.実例.
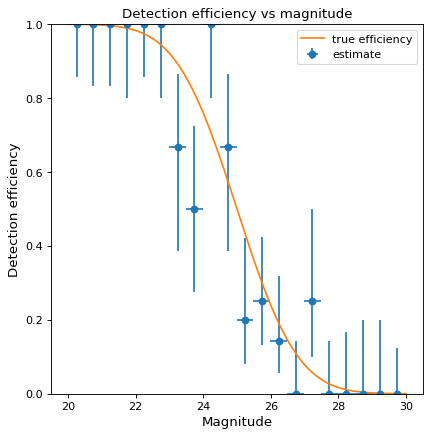
天文震源を検出する効率をマグニチュードの関数(すなわち、所与の震度で震源を検出する確率)と推定したいと仮定する。現実には,ランダムに振幅を選択したソースを大量に用意し,それらをシミュレーション画像に注入し,復元パイプの末端で検出されたソースを記録する可能性がある.玩具の一例として、ランダムに選択されたサイズ20~30のデータ点を100個生成し、既知の検出関数(ここでは誤差関数、サイズ25の場合の検出確率50%)を用いて“観察”する。
>>> from scipy.special import erf >>> from scipy.stats.distributions import binom >>> def true_efficiency(x): ... return 0.5 - 0.5 * erf((x - 25.) / 2.) >>> mag = 20. + 10. * np.random.rand(100) >>> detected = binom.rvs(1, true_efficiency(mag)) >>> bins, binshw, p, perr = binned_binom_proportion(mag, detected, bins=20) >>> plt.errorbar(bins, p, xerr=binshw, yerr=perr, ls='none', marker='o', ... label='estimate')
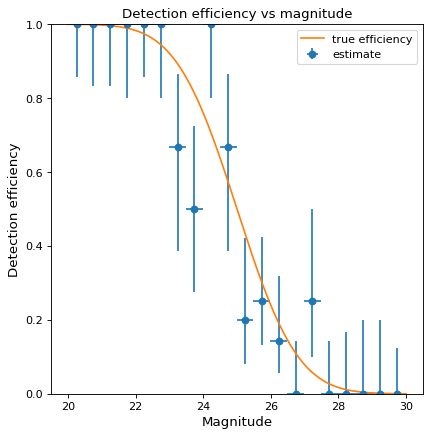
上の例ではWilson信頼区間を用いて不確実性を計算している
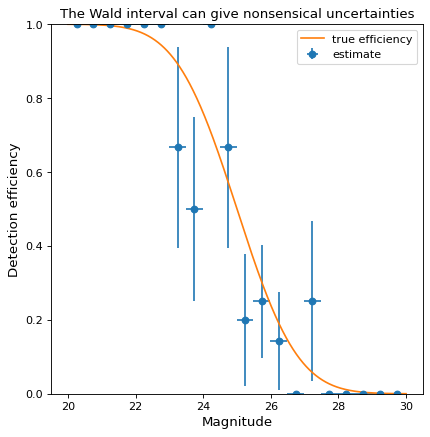
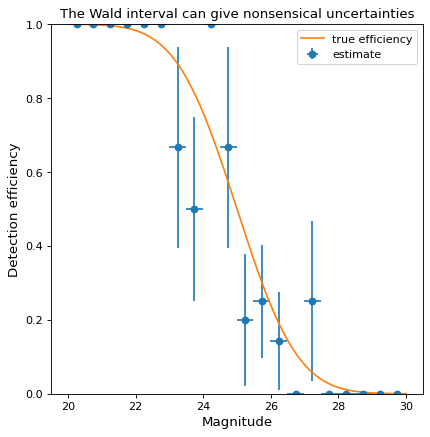
perr各倉位において(各信頼区間の定義を参照されたい)binom_conf_interval)である。一般的な代替方法の1つはWald Intervalである.しかし,効率が0または1に近い場合,Wald間隔は無意味な不確実性を与えるため,Wald間隔は無意味な不確実性を与える. not おすすめです。一例として、以下の例では上記と同様のデータを示すが、Wilson間隔ではなくWald間隔を用いて計算する。perr:>>> bins, binshw, p, perr = binned_binom_proportion(mag, detected, bins=20, ... interval='wald') >>> plt.errorbar(bins, p, xerr=binshw, yerr=perr, ls='none', marker='o', ... label='estimate')
{kind=link}
{kind=link}
{kind=link}
{kind=link}