時系列を読み書きする¶
内蔵カードリーダ¶
自.自.以来. TimeSeries そして BinnedTimeSeries はい子類です。 Table 彼らは持っている read() そして write() 時系列をファイルから読み出して書き込む方法を使用することができる。良いフォーマットを定義したリーダーが含まれています astropy.timeseries. For instance we have readers for light curves in FITS format from the Kepler そして TESS 任務。
例を引く¶
このケプラーを用いた時系列のデモでは、サンプルファイルを取得することから始めます。
from astropy.utils.data import get_pkg_data_filename
example_data = get_pkg_data_filename('timeseries/kplr010666592-2009131110544_slc.fits')
注釈
ここで提供される照明曲線は、例示的な目的のために手動で選択される。Pythonを使用して科学目的のための他のケプラー光線曲線を取得するには、参照されたい astroquery 付属小包です。
これは設定されます example_data ファイルのファイル名をダウンロードするように設定されています(したがって、読み込むファイルのファイル名に置き換えることができます)。そして、以下のコマンドを使用して時系列を読み出すことができる。
from astropy.timeseries import TimeSeries
kepler = TimeSeries.read(example_data, format='kepler.fits')
時系列が正しく読み込まれているかどうかを確認することができます:
import matplotlib.pyplot as plt
plt.plot(kepler.time.jd, kepler['sap_flux'], 'k.', markersize=1)
plt.xlabel('Julian Date')
plt.ylabel('SAP Flux (e-/s)')
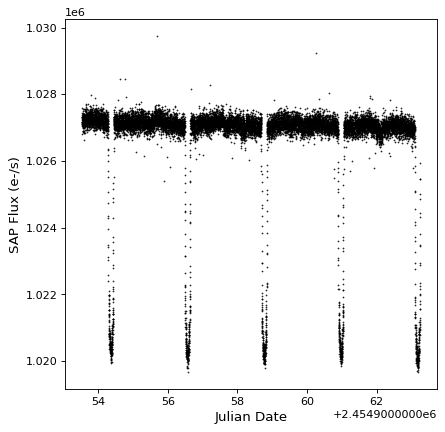{kind=link}
{kind=link}
通常の光線曲線形式を読む¶
現在いくつかのフォーマットしかありません astropy これは,時系列を格納するために良好なフォーマットが多く記録されていないためである.したがって、多くの場合、あなたはまずもっと汎用的なものを使用しなければならないかもしれない。 Table 類(参照) 読み書き表オブジェクト )である。実際には TimeSeries.read そして BinnedTimeSeries.read 方法は舞台裏でこの操作を行うことができる.どの時系列リーダもテーブルを読み取ることができない場合、これらの方法は、いくつかのデフォルト設定を使用しようと試みる。 Table リーダは,ユーザに重要列の名前を指定するように要求する.
実例.¶
もしあなたが名前を読んでいるなら sampled.csv その中で呼び出し時間列 Date また、ISO文字列であれば、以下の動作を行うことができる。
>>> from astropy.timeseries import TimeSeries
>>> from astropy.utils.data import get_pkg_data_filename
>>> sampled_filename = get_pkg_data_filename('data/sampled.csv',
... package='astropy.timeseries.tests')
>>> ts = TimeSeries.read(sampled_filename, format='ascii.csv',
... time_column='Date')
>>> ts[:3]
<TimeSeries length=3>
time A B C D E F G
object float64 float64 float64 float64 float64 float64 float64
----------------------- ------- ------- ------- ------- ------- ------- -------
2008-03-18 00:00:00.000 24.68 164.93 114.73 26.27 19.21 28.87 63.44
2008-03-19 00:00:00.000 24.18 164.89 114.75 26.22 19.07 27.76 59.98
2008-03-20 00:00:00.000 23.99 164.63 115.04 25.78 19.01 27.04 59.61
バイナリ時系列を名前のファイルから読み込んでいる場合 binned.csv 柱があります time_start 開始時間と bin_size 各ゴミ箱のサイズが与えられると、以下の操作が実行されます。
>>> from astropy import units as u
>>> from astropy.timeseries import BinnedTimeSeries
>>> binned_filename = get_pkg_data_filename('data/binned.csv',
... package='astropy.timeseries.tests')
>>> ts = BinnedTimeSeries.read(binned_filename, format='ascii.csv',
... time_bin_start_column='time_start',
... time_bin_size_column='bin_size',
... time_bin_size_unit=u.s)
>>> ts[:3]
<BinnedTimeSeries length=3>
time_bin_start time_bin_size ... E F
s ...
object float64 ... float64 float64
----------------------- ------------- ... ------- -------
2016-03-22T12:30:31.000 3.0 ... 28.87 63.44
2016-03-22T12:30:34.000 3.0 ... 27.76 59.98
2016-03-22T12:30:37.000 3.0 ... 27.04 59.61
参照の文書 TimeSeries.read そして BinnedTimeSeries.read もっと細かいことを知っています。
あるいは、自分のコードを使って表に読み込み、構造することもできます TimeSeries 対象は,中で述べたとおりである 時系列の作成 別の時系列を同じフォーマットで書くことはできませんが。
通常のフォーマットのリーダ/ライタを作成した場合は、いつでも投稿してください astropy もういいよ。