時系列の処理と解析¶
時系列を組み合わせる¶
♪the vstack() そして hstack() 中の関数 astropy.table モジュールは、時系列を異なる方法でスタックするために使用されてもよい。
実例.¶
属性は、“垂直”または行ごとに時系列をスタックすることができる。 vstack() 関数(ただし、サンプリングされた時系列は、入庫された時系列と組み合わせることができず、その逆も同様であることに留意されたい)。
>>> from astropy.table import vstack
>>> from astropy import units as u
>>> from astropy.timeseries import TimeSeries
>>> ts_a = TimeSeries(time_start='2016-03-22T12:30:31',
... time_delta=3 * u.s,
... data={'flux': [1, 4, 5, 3, 2] * u.mJy})
>>> ts_b = TimeSeries(time_start='2016-03-22T12:50:31',
... time_delta=3 * u.s,
... data={'flux': [4, 3, 1, 2, 3] * u.mJy})
>>> ts_ab = vstack([ts_a, ts_b])
>>> ts_ab
<TimeSeries length=10>
time flux
mJy
object float64
----------------------- -------
2016-03-22T12:30:31.000 1.0
2016-03-22T12:30:34.000 4.0
2016-03-22T12:30:37.000 5.0
2016-03-22T12:30:40.000 3.0
2016-03-22T12:30:43.000 2.0
2016-03-22T12:50:31.000 4.0
2016-03-22T12:50:34.000 3.0
2016-03-22T12:50:37.000 1.0
2016-03-22T12:50:40.000 2.0
2016-03-22T12:50:43.000 3.0
注意してください vstack() 自動的にソートされることもなく、重複項も削除されません-これはあなたが後で明示的に実行しなければならない操作です。
時系列は、他のテーブル“レベル”または列ごとに組み合わされてもよい。 hstack() 関数、これらは時系列であるべきではない(複数の時間列が混同されるので):
>>> from astropy.table import Table, hstack
>>> data = Table(data={'temperature': [40., 41., 40., 39., 30.] * u.K})
>>> ts_a_data = hstack([ts_a, data])
>>> ts_a_data
<TimeSeries length=5>
time flux temperature
mJy K
object float64 float64
----------------------- ------- -----------
2016-03-22T12:30:31.000 1.0 40.0
2016-03-22T12:30:34.000 4.0 41.0
2016-03-22T12:30:37.000 5.0 40.0
2016-03-22T12:30:40.000 3.0 39.0
2016-03-22T12:30:43.000 2.0 30.0
時系列順序付け¶
時系列を定位置ソートして使用することができる sort() 方法は、例えば Table **
>>> ts = TimeSeries(time_start='2016-03-22T12:30:31',
... time_delta=3 * u.s,
... data={'flux': [1., 4., 5., 3., 2.]})
>>> ts
<TimeSeries length=5>
time flux
object float64
----------------------- -------
2016-03-22T12:30:31.000 1.0
2016-03-22T12:30:34.000 4.0
2016-03-22T12:30:37.000 5.0
2016-03-22T12:30:40.000 3.0
2016-03-22T12:30:43.000 2.0
>>> ts.sort('flux')
>>> ts
<TimeSeries length=5>
time flux
object float64
----------------------- -------
2016-03-22T12:30:31.000 1.0
2016-03-22T12:30:43.000 2.0
2016-03-22T12:30:40.000 3.0
2016-03-22T12:30:34.000 4.0
2016-03-22T12:30:37.000 5.0
再サンプリングする.¶
私たちが提供するのは aggregate_downsample() 自己定義関数(平均値、中央値など)を使用して、時系列内の値を等しい時間のボックスに入れるために使用することができる関数。この操作は1つに戻ります BinnedTimeSeries それがそうです。これは、例えば、不確実性を有する列を他の値とどのように区別するかを知らず、指定されたカスタム関数をすべての列に盲目的に適用する基本関数であることに留意されたい。
例を引く¶
以下の例はどのように使用するかを示す aggregate_downsample() ケプラータスク中の光線曲線をメジアン関数を用いて20分間のボックスに入れる.まず,以下のようにデータを読み込む:
from astropy.timeseries import TimeSeries
from astropy.utils.data import get_pkg_data_filename
example_data = get_pkg_data_filename('timeseries/kplr010666592-2009131110544_slc.fits')
kepler = TimeSeries.read(example_data, format='kepler.fits')
(参照されたい) 時系列を読み書きする 読み込みデータに関するより詳細な情報).次に、以下の方法を用いてダウンサンプリングを行うことができる。
import numpy as np
from astropy import units as u
from astropy.timeseries import aggregate_downsample
kepler_binned = aggregate_downsample(kepler, time_bin_size=20 * u.min, aggregate_func=np.nanmedian)
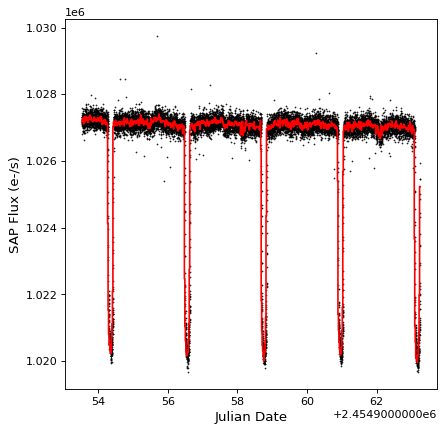
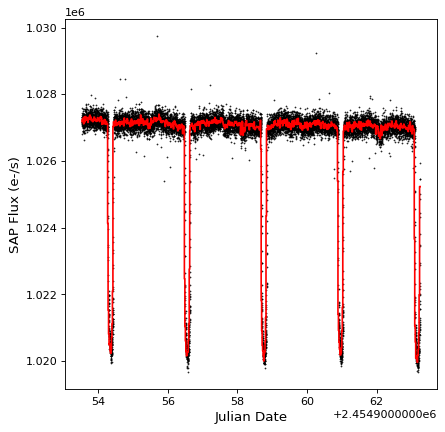
結果を見てみましょう
import matplotlib.pyplot as plt
plt.plot(kepler.time.jd, kepler['sap_flux'], 'k.', markersize=1)
plt.plot(kepler_binned.time_bin_start.jd, kepler_binned['sap_flux'], 'r-', drawstyle='steps-pre')
plt.xlabel('Julian Date')
plt.ylabel('SAP Flux (e-/s)')
{kind=link}
{kind=link}
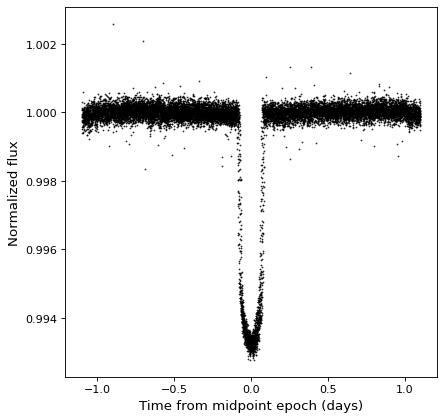
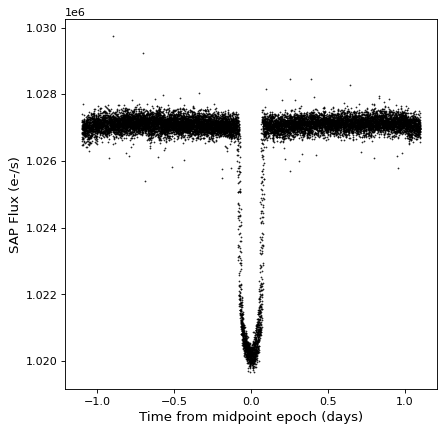
折り畳む¶
♪the TimeSeries 種類が一つある fold() 相対的および折り畳み時間軸を有する新しい時系列を返すために使用することができる方法。この方法は周期を Quantity 1つの紀元を選択することができます Time ゼロ時間オフセットを定義しています
kepler_folded = kepler.fold(period=2.2 * u.day, epoch_time='2009-05-02T20:53:40')
plt.plot(kepler_folded.time.jd, kepler_folded['sap_flux'], 'k.', markersize=1)
plt.xlabel('Time from midpoint epoch (days)')
plt.ylabel('SAP Flux (e-/s)')
{kind=link}
{kind=link}
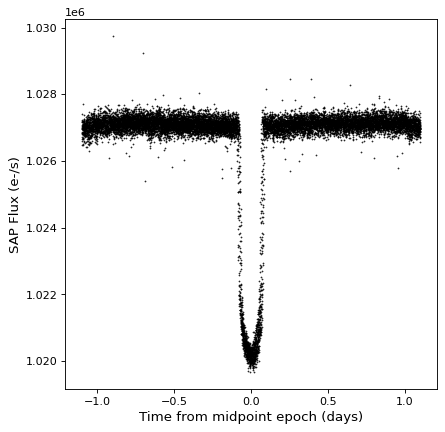
この例では,たまたま先の周期図解析から周期と中点が分かっていることに注意されたい.中の例を参照されたい 時系列. (astropy.timeseries ) あなたはどうするかもしれません。
算数をする.¶
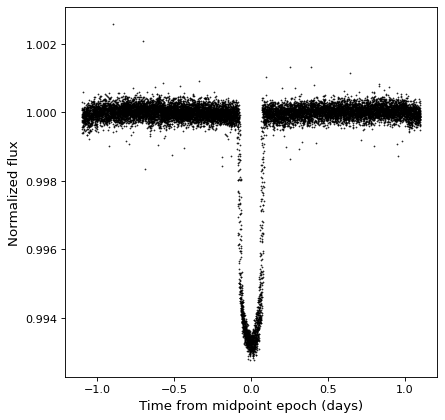
自.自.以来. TimeSeries 対象は子類 Table これらは、任意のデータ列上の算術演算を自然にサポートする。一例として,先の例で見た折り畳みケプラー時系列を例に,σ−クロッピングの中央値に正規化することができる。
from astropy.stats import sigma_clipped_stats
mean, median, stddev = sigma_clipped_stats(kepler_folded['sap_flux'])
kepler_folded['sap_flux_norm'] = kepler_folded['sap_flux'] / median
plt.plot(kepler_folded.time.jd, kepler_folded['sap_flux_norm'], 'k.', markersize=1)
plt.xlabel('Time from midpoint epoch (days)')
plt.ylabel('Normalized flux')
{kind=link}
{kind=link}